This is another one of those items that is really just for myself, because it will certainly come up again…
I have a Synology NAS I use for backups, and once in awhile you end up with a filesystem error that it can’t fix, so the recommended solution is to copy everything off the backup volume, reformat the drives/volume and copy everything back (which I’ve done a couple times over the years). Most recently, one of the hard drives failed in the RAID (no biggie, popped in a new one and it rebuilt itself as expected), but also ended up with some filesystem errors for whatever reason. I decided this time I was going to figure out how to fix it without copying everything off and back on to it.
It’s currently running DSM 7.1.1, so what I did may or may not work for other versions (and I should also point out that this post is intended as a reminder to myself, I don’t recommend anyone doing it to their own system).
Step 1: Enable Telnet on the NAS (you can’t do this over SSH because of how some processes work, not going to go into the details here).
Step 2: Telnet in and shut down PostgreSQL via (the PostgreSQL service will automatically restart, preventing the volume from being unmounted): sudo systemctl stop pgsql
Step 3: Unmount the volume: sudo umount -f -k /volume1
I have two XServe G5 servers that I haven’t used as web/database servers in a long time, but I do use them for other stuff (backup destination, historical monitoring of other hardware, etc.)
I haven’t had any problems with them in the 11 years that I’ve had them, except now both died within a week of each other (specifically, both power supplies died). Which I guess says something about manufacturing consistency to have both die at the same time. 🙂
I had a new spare because way back in the day I bought the XServe service parts kit (included spare motherboard, power supply, fans, etc.), so getting one of them back online was no big deal. Searching around to buy another one, and the power supplies are like $400. Yeah, no thanks… not for a machine that probably isn’t even worth that much as a whole.
So instead of spending $400, let’s see how nerdy I can be and just replace all the capacitors in the power supply for closer to $10 in parts and see what happens… You could actually get the parts for $1-2 if you are okay with getting junky capacitors, but probably a good idea to replace capacitors in a server power supply with good ones. 🙂
The place I got my capacitors didn’t have the 1uF or 10uF radial ones I needed, so I ended up getting a tantalum capacitor for the 1uF one and then a radial 10uF 50V instead of the 25V (you can use a higher voltage as long as the microfarad rating is the same).
First off, let me say that I love CloudFlare… and coming from me, that probably means something because there aren’t a lot of third party services that I think are great. But CloudFlare is one of those.
That being said, I still have a list of things I wish CloudFlare did (or did differently):
Have a “failover host” option for individual DNS records. For example route to host X, but if host X is down, route to host Y. Yes, I know you can do DNS management with the CloudFlare API, and I built a system that monitors servers and switches them if needed via DNS API. Just would be simpler if we had a “failover host” option.
Allow wildcard domain records to route through CloudFlare. This would be way more convenient.
Make the Authy two-factor code last longer (like 30 days for that computer?). It’s obnoxious that you have to generate a new two-factor code while being on the same computer every other day.
Geotargeting granularity. It would be nice if CloudFlare could geotarget more than the country… like long/lat/city level would be nice.
WebSockets support. Yes, I know it supports WebSockets for Enterprise users… and while I’m on a paid plan, I’m not on the Enterprise tier. Update: from the comments on this blog post, it looks like it might be coming. Yay!
Prepayment. For paid plans, I don’t know what happens if your monthly payment doesn’t go through for some reason, but I don’t want to find out. It would be nice if you could just be like, “I want to prepay for the next year so there’s no service interruption”.
Use HTTP/2 To Origin. Cloudflare doesn’t use SPDY or HTTP/2 to the origin server even when available. See: this tweet
Sync Data Centers. Cloudflare data center caching is great, but as more and more data centers come online, the benefit diminishes. Right now there are 74 Cloudflare data centers, which means a resource is requested 74 times (once per data center) for caching.
Email routing. It would be nice if you didn’t have to expose your server’s true IP addresses when sending an email (or just from your SPF records in your DNS). Having a service that lets your mail servers relay email through and erase the originating IP from the email header in the process would be super fantastic. Probably would be problematic because of potential spam implications, but it sure would be nice to have truly hidden server IPs without needing to get separate servers in a separate location for email.
CloudFlare is super rad and if you own a website without using it (even their free plan), you are doing it wrong. 🙂
So I had an issue where ndb_restore was utterly failing and made it so it was impossible to restore ndbcluster tables from a backup. Trying to use it was flooding us with all sorts of sporadic errors…
[NdbApi] ERROR — Sending TCROLLBACKREQ with Bad flag
—————
theNoOfSentTransactions = 1 theListState = 0 theTransArrayIndex = 5
—————
Temporary error: 410: REDO log files overloaded (decrease TimeBetweenLocalCheckpoints or increase NoOfFragmentLogFiles)
—————
Temporary error: 266: Time-out in NDB, probably caused by deadlock
—————
Finally was able to work it out, but man, can I just say that ndb_restore really could use an overhaul to make it a little more friendly? Okay, go! 🙂
This is mostly a reminder to myself… but maybe someone else will find it useful as well.
I migrated some databases to ndbcluster (some of the tables were fairly decent sized… 9GB for 1 table spanning 220M records), and was running into a problem where an ALTER TABLE to change the storage engine was spewing out some cryptic error message like so:
Cryptic mainly because it was coming from MyISAM, which doesn’t have record locking. Long story short is it’s not a setting in your my.ini file for mysqld, rather a setting in your config.ini for ndbd. The TransactionDeadlockDetectionTimeout setting defaults to 1200 (1.2 seconds), I ended up raising it to 24 hours just for purposes of migrating existing tables to ndbcluster (the setting of 86400000 ms is 24 hours).
Being relatively new to MySQL Cluster, it was also a good opportunity to practice making a config change and doing a rolling restart of the ndbd nodes to have no downtime.
So this has been driving me mad since I installed Mac OS X 10.7… Any time Cacti tried to output a graph, it would output, but it was painfully slow (like 30 seconds)… prior to installing 10.7, it was a fraction of a second.
Anyway… long story short is apparently RRDtool pulls the list of fonts from the system, and since it was running as the _www user, it was unable to write a the font cache to disk to make future font access fast.
Logging in as root and running the “fc-list” command to get a list of installed fonts fixed the problem. The first time it ran it took 30 seconds (imagine that! heh), and subsequent times it was instant. And Cacti graphs are back to being instant. Hopefully this helps someone…
Seagate is still not producing the hard drives I want for new servers in sufficient quantity, but they do seem to be actually producing them now. I’ve seen places where I can get 30 of them lately… but I need 72.
I’m assuming I’ll be able to get them relatively soon and have started to think about how I want to lay the servers out architecturally.
As far as hardware goes, gigabit ethernet just really isn’t that fast these days… Real world use has being able to pass about 80MB/sec (theoretical maximum is about 110MB/sec). When you have a cluster of servers passing massive amounts of data amongst themselves, 80MB/sec just doesn’t cut it. Which is why the servers have Infinband QDR (40Gbit interconnects), so they should be able to pass 3.5GB/sec (ish) between themselves.
For software/services, I’m thinking maybe 12 identical servers that are more or less service agnostic… with each server being a web server, MySQL Cluster data node and a MySQL Cluster SQL node. Then each server could probably be setup to handle 10,000 concurrent HTTP connections as well as 10,000 DB connections (1 per HTTP connection). With 12 servers, you could have the capacity of 120k concurrent web connections, 120k DB connections capable of doing millions of SQL queries/sec. If you need more capacity with anything, you could just bring online additional agnostic servers.
This of course is just in theory… who knows how it will test out in actual use, but it does seem like something worth testing at least.
I had a switch that “lost” it’s operating system and was stuck in a reboot loop. Long story short is I needed to upload the OS via a direct serial connection to fix it. I didn’t have a Windows machine available, so I used my Mac and a Keyspan USA-19 (USB -> DB9) thingie (heh). This is mostly a note for myself in case I need to ever do it again, and I forget.
Things that did not work…
ZTerm let me get to the console just fine, but uploading the firmware with XModem failed for some reason (and you only found out it failed after a 3.5 hour upload time).
Keyspan device on Windows via Parallels (from all the Googling I did, apparently it’s just an known issue with that piece of hardware and Parallels and the drivers will not recognize it).
Virtual serial port in Windows/Parallels via a app called SerialClient (it was very difficult to find this app since the site that made it doesn’t exist anymore… people running Parallels said this worked for them, but it was many years ago… so maybe it was an older version of Mac OS X. Either way, I couldn’t get the app to “connect”.).
What DID work (thank God because I was running out of options)…
Download/compile/install lrzsz via ./configure;make;make install.
From Terminal: screen /dev/tty.Keyserial1 57600
Hit CONTROL+A
Type: :exec !! lsx -b -X ~/firmware_image.ros
It was infinitely faster than ZTerm (about 15 minutes vs. 3.5 hours), but more importantly it actually WORKED.
Sadly, 12GB in a server just isn’t what it used to be and the database servers are really starting to feel strained as they beg for more memory. Handling ~25GB of databases on servers with 12GB is just no bueno. I thought of upgrading the RAM in the blades, but the maximum RAM the BIOS supports is 16GB, and all the DIMM slots are in-use… so it more or less would mean tossing all the existing RAM and buying 160GB of new RAM. In the end spending that much money to gain 4GB per server isn’t really worth it (especially since 16GB wouldn’t really be enough either).
I started to do a little research on what would be some good options for upgrades… I think I want to stay away from blades simply because we did have the daughter card in the chassis fail once which took down all 10 blades (the daughter card controls the power buttons). Buying 2 complete sets of blades/chassis is overkill just so you have stuff still up if one complete chassis goes down. The “must haves” on my list are hot swappable drives with hardware RAID, hot swappable redundant power supply, some sort of 10Gbit/sec (or higher) connectivity for communicating between servers. On top of it all, the servers need to be generally “dense” (I don’t want to take an entire rack of space).
PowerEdge C6100
The Dell C6100 actually looked really nice at first glace…
Pros
Super dense (4 servers in a 2U package)
Redundant power supplies (hot swap)
24 (!!) hot swap drives
Supports 10GbE or even QDR Infiniband (40Gbit/sec
Cons
Age – the server itself came out about 18 months ago without any refresh. That means you have hard drive options and CPU options that are a year and a half old
Price – OMG… a single unit loaded up with 4 nodes, drives, RAM, Infiniband, etc. works out to $54,709 (before tax).
The age factor really becomes an issue when it comes to the disk drives… you can get 15k rpm drives in a 2.5″ form factor, but Dell only offers 146GB models (there are 300GB models now). The CPU isn’t really too bad… Dell’s fastest offering is the Xeon X5670… 2.93Ghz, 6 core @95 watts (wattage is important because of so much stuff crammed in there). There is a slightly faster 95 watt, 6 core processor these days… the Xeon X5675… the same thing basically, just 3.06Ghz. 0.13Ghz speed difference isn’t a huge deal… but the hard drive difference is a big deal.
I started to think… well maybe I could just order it stripped down and then I could just replace the CPU/hard drives with better stuff. Doing that, you still end up spending about $60,000 because you end up with 8 Xeon processors (valued at about $1,500 each that you just are going to throw away).
Then I started to think harder… Wait a minute… Dell doesn’t even make their own motherboards (at least I don’t think so)… so maybe I could find the source of these super dense motherboards and build my own systems (or just find the source of something similar… which ended up being the case).
SuperServer 2026TT-H6IBQRF
What do we have here??? The Supermicro SuperServer 2026TT-H6IBQRF is more or less the same thing… 4 servers per 2U, hot swap hard drives, same BIOS/chip/controllers… supports the same Xeon processor family (up to 95 watts)… And as a bonus, Infiniband QDR is built in (it’s a $2,596 add-on for the Dell server) as well as an LSI MegaRAID hardware RAID card (a $2,156 add-on for the Dell server).
So let’s add up the cost to build one of these things with the CPU/hard drives I actually would WANT…
Chassis (includes 4 motherboards, 2 power supplies, hard drive carriers, etc. – $4,630.98
Xeon X5675 3.06Ghz CPU – $1,347.84 each, so $10,782.72 for 8
8GB ECC/Reg DIMM – $124.26 each, so $5,964.48 for 48
600GB Seagate Savvio 10K.5 – $391 each, so $9,384 for 24 (also 410% more capacity, 21% faster and 20% more reliable than the 146GB options from Dell)
Add It All Up…
$30,761.88 would be the total cost (a savings of $24,138.82) and in the end you get slightly faster CPUs and *way* better hard drives. So in a single 2U package, you end up with 48 Xeon cores at 3.06Ghz, 384GB of 1333Mhz memory, 14.4TB of drive space (9.6TB usable after it’s configured as double redundant parity striping with RAID-6… which should be able to do more than 750MB/sec read/write). 8 gigabit ethernet ports and 4 Infiniband QDR (40Gbit) I/O.
Get 2 or 3 of those rigs, and you have some nasty (in a good way) servers that would be gloriously fun to run MySQL Cluster, web servers and whatever else you want.
So I was in a situation where I want to upgrade the operating system on 10 blade servers that are in a data center. The problem is I really didn’t want to sit there and install the new operating systems on each one by one. The other issue is the servers don’t have CD/DVD drives in them since are blades.
I have a couple older Xserve G5s in the facility, so I figured why not use them as network boot servers for the Linux machines? By default OS X Server has a service for NetBoot (which is not the same thing and can really only be used to boot other Mac machines). But Mac OS X Server also has all the underlying services already installed to make it able to be a server for PXE booting from normal Intel BIOS.
So what network services do we need exactly (at least for how I did it)? DHCP, NFS, TFTP and optionally Web if you do an auto-install like I did.
Preface
This was written up in about 5 minutes mostly so I wouldn’t forget what I did in case I needed to do it again. Some assumptions are made like you aren’t completely new to Linux/Mac OS X administration. You can also have pxelinux boot to a operating system selection menu and some other things, but for what *I* wanted to do, I didn’t care about being able to boot into multiple operating systems/modes.
Setting Up The Server
Mac OS X Server makes it really simple to get DHCP, NFS and Web servers online since the normal Server Admin has a GUI for each.
Mac OS X has a TFTP server installed by default, but there it’s not running by default and has no GUI. You can of course enable/configure it from the shell, but just to make things simple, there is a free app you can download that will make configuring and starting the TFTP service simple (the app is just a configuration utility, so it does not need to run once you are finished, so adds no overhead). You can grab the app over here.
Files Served By TFTP
I was installing openSUSE 11.4, so that is what my example revolves around… most Linux installations should be similar, if not identical. First, make sure you have syslinux, which you probably already have since most Linux distributions install it by default.
Copy /usr/share/syslinux/pxelinux.0 to your Mac OS X TFTP Server: /private/tftpboot/pxelinux.0
Create a directory on your Mac OS X Server: /private/tftpboot/pxelinux.cfg, and then create a file named default within that folder with the following:
Obviously change the IP address to your Mac OS X Server IP address. The autoyast part is optional and only needed if you have an auto-configuration file for YaST.
Now we want to grab two files from the installation DVD/.iso so we have the “real” kernel.
Copy /boot/x86_64/loader/linux from the installation DVD to your Mac OS X TFTP Server: /private/tftpboot/osuse11-4.krnl (notice the file rename)
Copy /boot/x86_64/loader/initrd from the installation DVD to your Mac OS X TFTP Server: /private/tftpboot/osuse11-4.ird (notice the file rename here too)
Special Options For DHCP Server
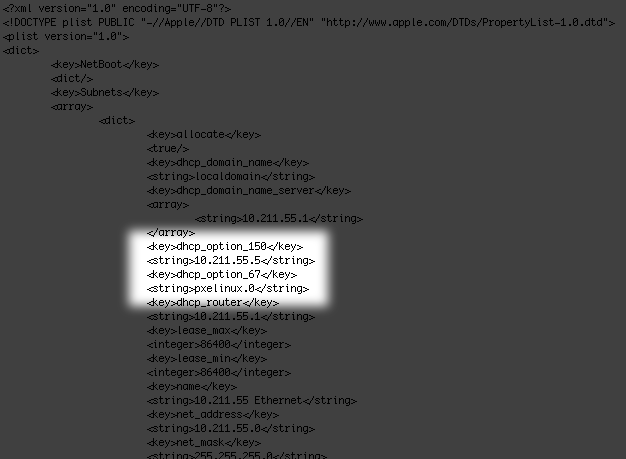
There is not a GUI for adding special options to the DHCP server, but it’s easy enough to add them manually. Just edit the /etc/bootpd.plist file, and add two keys/values to it (option 150 is the IP address of your TFTP server, option 67 is the kernel file name the TFTP server is serving):
NFS Sharing Of Installation DVD
Edit your /etc/exports file, and add the following line to it:
/images/opensuse10-4 -ro
Then just copy the contents of the entire installation DVD to /images/opensuse10-4. You can of course just do a symlink or something if you want.
Cross Your Fingers…
Hopefully if all goes well, you should see something along the lines of this when you choose to network boot a machine (for purposes of this video, I did it in a virtualized environment of Parallels so I didn’t need to boot any running servers):
Note: This was moved from blogs.digitalpoint.com to here, because well… blogs.digitalpoint.com is no longer a sub-domain we use (user blogs were wiped when we migrated to XenForo).
I’ve heard people claim they were banned from AdSense unfairly for this, that and whatever other reason though the years… and to be honest, I just chalked it up to them doing something they shouldn’t have been and just not admitting it.
Low and behold, it *can* happen to even larger publishers (I believe we were approaching over 1,000,000,000 [yes, billion] AdSense impressions over the years). Note: I can’t confirm the exact number because, well… my AdSense account was disabled.
We get advertising inquires daily and we even go so far as directing people to AdWords and explain to them how to use Site/Placement targeting if they wish to advertise on digitalpoint.com. It’s less money for us, but in the end it’s easier and less to manage. I would guess Google has gained at least 200 NEW AdWords advertisers because of this.
The Warnings
In the last month, we received 30 warnings for running AdSense ads on non-compliant websites (gambling related). These are sites that I don’t own, have no affiliation with, nor do I know who the owner is. I have no idea why someone would want to use my AdSense publisher ID on their site, but I guess that’s beside the point really. AdSense allows you to set a whitelist of your sites just so this doesn’t cause problems. We have used this whitelist for a long time (since we first heard about it), and none of these gambling related sites were on our whitelist.
Hell, I even got an email from Google *because* I use a whitelist (and STILL didn’t turn off the whitelist function)…
Your Allowed Sites settings blocked $220 in earnings last week
We noticed that you’ve been receiving ad activity on sites which aren’t included in your Allowed Sites list. If a URL displaying your AdSense ad code is not on your Allowed Sites list, ads will still be displayed, but you won’t receive any earnings for that URL.
For your reference, sites that display your ad code, but aren’t included in your Allowed Sites list generated roughly $220 from May 2 through May 8.
My Response
After seeing a zillion of these notices coming in, I responded and let them know that these are not my sites and that I use their whitelisting feature (and that none of these sites are on my whitelist).
Sarah H. from Google’s AdSense Team responded back a couple weeks later letting me know that, “If that site or URL is not in the Allowed Sites List within your account, no further action is needed and this issue won’t negatively affect your account in any way.“. Alright… no further action is needed.
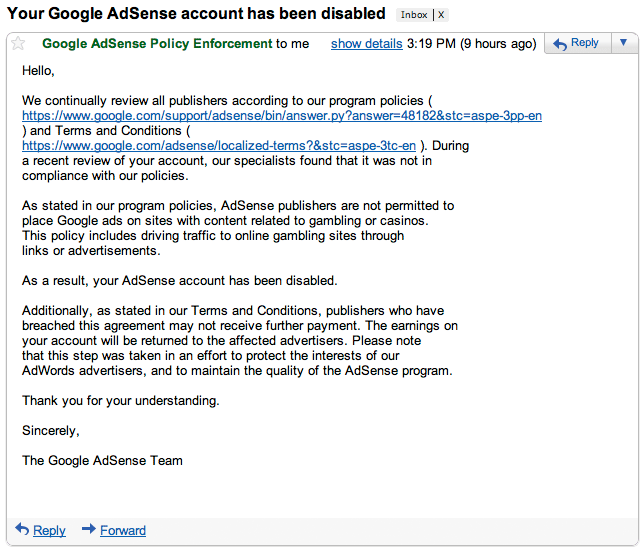
Account Disabled
Fast forward a couple days and I get this email from Google letting me know my account is now disabled because of violations of program policies… specifically, AdSense publishers are not permitted to place Google ads on sites with content related to gambling or casinos. I *still* don’t own a gambling/casino related site (nor have I ever), so I’m assuming it’s related to the 30 warnings I got in the last month for someone else trying to run my publisher ID on their sites.
While I still think the majority of people who claimed to have their AdSense account unfairly terminated are probably just whiners that got caught doing something they shouldn’t be, I can say for 100% certainty now that it can (and clearly does) happen sometimes.
I guess it’s time to finally start managing advertising in-house… Just one more thing to add to the “to-do” list. /sigh
Okay, gonna go ahead and upgrade the Digital Point Forums to vBulletin 3.8.3… Since so many of you are freaks and are on it 24/7, I made this post to keep you up to date on what’s going on (I’ll update it periodically throughout the process). You can also use this blog post as the new temporary forum for all your discussion needs while I do the upgrade. hah
3:26 am – Reading and posting seems to work… I suppose that’s good enough for now (still working on the other stuff, but don’t need to force everyone off to do it).
3:24 am – Skimming over various areas of the forum to see if things (mostly) work. I could let you guys in before the templates are fully updated possibly.
3:22 am – New moderator permissions set
3:17 am – Static CSS files located on single server in web cluster and spread around properly (I hate this about vBulletin BTW… gimme a hook location to do it please!)
3:09 am – Core upgrade done.
3:07 am – Recoded some of the upgrade scripts so they aren’t making that change to the reputation table. Will deal with issue this later instead.
3:00 am – Stupid reputation table was altered in 3.8.0 to not allow negative userids so it can accommodate 4 billion users instead of “only” 2 billion. Stupid. I used negative userids internally for some stuff. /thinking what to do about this…
2:55 am – First problem… reputation table alterations not going well. Going digging in raw database…
2:50 am – Running “ALTER TABLE pmtext” on DB servers. That’s a big one… going to get another beer.
2:49 am – Up to version 3.8.0 alpha 1
2:43 am – It’s almost 3am. If you are a cute girl reading this, please post your picture in the comments, k thanks.
2:41 am – I forgot we have to go through all versions to get to the newest… lol… going through 3.7.0 beta 4 at the moment.
2:40 am – Userlist rebuilding
2:36 am – Watching DB servers alter thread table for tagging support… (this is really boring)
2:34 am – Watching DB servers alter thread table for prefix support… /bored
2:30 am – New PHP files in place and synced across web server cluster
2:29 am – DB backup done
2:27 am – Thinking I might not have enough beer for this…
2:25 am – DB backup still running (it’s huge… many, many, many gigs)
Okay, so I decided not to blog for 2+ years to see if the spam blocker thing I made would work, and sure enough it did… After 2+ years, not a single spam comment got through… I’d say that was pretty good, eh?
On a better note, I have 2 years of life to write about now… stay tuned… 🙂
The comment spam on my blog here was getting to the point of just being silly… around 4,000 spam comments per day (breaks down to about one every 15 seconds 24/7).
I decided to try and do something about it so I don’t have to weed through them manually (the time consumption on this task is one of the biggest reasons I don’t post as often as I used to).
So let’s see how it works… if you see me posting more often, then you know it worked. 😉
Okay, is anyone tired of my server admin tips yet? Yes? Too bad.
Monitor everything… Put as much info at your finger tips as easily as possible. Put that info in a place where you will always be looking at it for some reason. For example, I made a vBulletin plug-in that monitors 4 memcached servers (including a latency test it runs) as well as 10 blade servers. This shows every time I’m in the admin of the forum (which is a lot), so I can’t help but to not see it.
I wrote a little daemon that runs on my servers that can quickly report back whatever info I want (time, disk RAID status, server load, MySQL replication status, etc.)
The more info you have in one place (especially when you run a bunch of servers), the easier it is to see anything wrong. For example, I had an issue with a web server serving requests slow one day… it ultimately ended up not being a problem with the web server, but the memcached server it was using. The latency test was showing ~2,000 ms latency (2 seconds) vs. the normal 0.5 ms (1/2000 of a second).
And be proactive about monitoring stuff… don’t wait until something bad happens to start doing it! Then it’s too late.
Yay, more server admin fun! 🙂 Here’s a useful *nix command that will let you determine what system calls a program uses… For example, I wanted to double check that libevent calls within memcached were using epoll() and select() or poll() calls (epoll scales better) on my SuSE Linux machines…
Purely out of necessity, I’ve become a system administrator/architect for digitalpoint.com servers… and a few people have been asking me for general admin tips to make things stable and scalable, so here’s a good one for you…
memcached is a distributed memory caching system that allows multiple servers to access the same shared memory (you can use it just for single local server too of course). You can cache pretty much anything… SQL query results (especially ones that can’t hit indexes), dynamically generated web pages, dynamic RSS feeds, etc.
If you compile the memcache() functions/class directly into PHP, you have a an easy (yet powerful) way to incorporate it.
For example, let’s say I have some existing code that makes a call to some sort of API (I use memcached for the keyword suggestion tool in this way)… you can add a couple lines of code to cache the results.
Now we are only hitting the API for the same keywords once every 24 hours… that setup utilizes 2 memcached servers working as a single entity for pooling and failover.
I use memcache for all sorts of things (this blog’s pages are cached for 60 seconds as another example because WordPress sucks, and protects against a massive influx of traffic [front-page digg for example]).
Temporary counters in Keyword Tracker (using decrement() for displaying remaining keywords on a “Check All”)
Recent forum topics that show on all the webmaster tools
vBulletin forum datastore
Any high-traffic site that is dynamically generated (especially if it includes SQL queries) could benefit from it… you could manage which memcache items need to be updated when you insert/update to the database, or an easy way to do it is just check the cache for the pages that potentially have high traffic… if they aren’t in the cache, put them in the cache with a certain expiration date. Then the page is dynamically generated no more often than the cache expiration time (in the case of this blog, the pages are generated no more than once every 60 seconds).
P.S. – Make sure you block outside access to your memcached port since there’s no authentication used!
I found some bugs in the web interface for a Linksys WRT54G router I bought to fix some 2Wire “issues”. One of the bugs just would give me a false error when trying to do something and keep the form from being submitted.
Anyway, the short version of this entry is that I found out that you can flash your Linksys with an entirely new firmware. Ultimately, I just wanted to fix the bug so I could do what the Linksys is supposed to do to begin with. But after installing it, it looks like you can do all sorts of other interesting things… like run crontab processes (since it’s Linux).
Anyway, if you have a Linksys WRT54G (they are pretty popular), and you are a dork, you may want to give it a go… but don’t blame me if you screw yours up (mine was fine).
Did I tell you how much I hate the 2Wire router/gateway you have to use for fiber Internet connections? You can’t get into the admin (which is web based) remotely, you can’t use DDNS so when your IP address changes weekly, you have no idea what it changed to, the firewall assumes you are an idiot and can’t do basic stuff with it, etc…
So the IP address changed over the weekend, and the only way to get the new IP is to drive out there and look to see what it is. On the way out there, I had an idea… why not buy a Linksys WRT54G broadband router and just route all in-bound traffic to it. Then you can use it’s firewall and DDNS functions. So that’s what I did… and it works *so* much better… remote admin access and everything else. I even tried to get tricky and route traffic to the Linksys and then right back to the 2Wire to see if I could get to it’s web admin remotely, but no such luck… It ends up redirecting it to a different URL (I’m assuming based on the client not being on the local network)… whatever that part isn’t that important anyway now.
In theory, Gmail’s spam filtering is supposed to get smarter as you “train” it by tagging spam emails that slipped through their spam filters. I’ve been anal about going through every single email and tagging every spam email as such in the hopes that it would get smarter. In reality, I think it might actually be getting dumber though, considering how much spam is making it to my inbox these days (it’s not a new thing BTW, I’ve been getting tons of spam in it for the last year, and it’s only been getting worse).
I doubt there’s an “easy” way to fix it (otherwise it would have been done), but I really wish Gmail would let us define our own custom spam rules. For example, if an email isn’t in English, it’s spam (for me anyway) considering I don’t read Russian, Chinese, Japanese, Korean, Greek, Hebrew, etc.
Check out the most recent emails in my inbox this morning (only 1 of them [the white line] is not spam).
Anyone know of some super awesome secret way to make a 2Wire Internet gateway also act as a dynamic DNS client? Since it’s a FTTP (fiber to the premises) gateway and not a “normal” DSL modem, I’m pretty sure I can’t just swap it out with something else that supports DynDNS.
The little I poked around the web interface, it seems pretty decent, other than no DDNS support. 🙁
The new servers and equipment were installed into the data center yesterday (I also had to move the existing servers/equipment to a new rack), so everything is physically at the data center now (it’s not actually in USE yet, but at least it’s at a place where I can start moving stuff over to them).
Kind of funny to see a load of servers that’s worth 100x as much as the car they are in. 🙂
A long time ago (when I was 17) I ruptured my spleen and they had to cut through my stomach muscles for the surgery. Well, apparently I had a weak spot just under my belly button from when my stomach muscles were sewn back together where I got a little hernia from lifting the servers earlier (I didn’t even notice it until about 10 hours later). I noticed a little bulge and knew I probably had a hernia of some sort from lifting that crap. Anyway… I just got back from Urgent Care (it’s a 24/7 place you can go in case you don’t know). 5 hours, 1 CAT scan and 3,827 games of Bejeweled on my cell phone later, I found out that I have a little piece of fat that popped through that weak (remember the spleen thing?) point.
Not that big of a deal… they are going to call me when they can take care of it with a quick little surgery.
More importantly, the new servers are in (oh yeah, I said that). 🙂
A bit of a blurry picture, before the cables were tied up.
Image stolen from Julien, who helped me move and install servers today.
So I was thinking about maybe doing MySQL fault tolerance and load balancing through hardware load balancers by setting up a virtual cluster for database reads and another for database writes. We could setup 2 master servers in a circular replication, making sure you only actually write to one at a time (define one as a hot spare in the load balancer’s “DB write cluster”, then the backup master takes over writes only if the primary master is down). That part is no problem… I don’ t have any questions there. 🙂
Now, let’s say we have three MySQL slave DB servers that read from the master through the load balancer’s “DB write” connection (again, they would only be reading from one at a time). But what I want to know is what would happen to the slave servers if you fail over the master -> slave connection to a different physical master server. Is this going to cause problems with the MASTER_LOG_POS position on the slaves if they fail over to a different master server?
Does anyone know much about the inner workings of MySQL’s master/slave setup and what happens in the event of a MASTER_LOG_POS conflict? I’m just thinking it would be nice to have a truly redundant database setup that was handled 100% through hardware (load balancers).
If no one knows, I guess that will be something I’ll be testing later this week. 🙂
The new servers will be going into the data center this week (Monday if I can coordinate it), so we are close (finally!).
Just got some stuff fine-tuned with them today… wrote a cluster-copy and cluster-exec app for copying stuff across all blades and executing something on all blades. Made an init.d script that alters the routing table at boot (for this) and also chooses which services to run based on an environment variable. So now I can change the “job” of a blade just by setting the environment variable.
So I’ve been fighting this networking crap for about a week now, and finally everything is working like it should. Just took a little editing of the underlying network routing tables.
“Hate” is a strong word, but in this case I think it’s appropriate…
I’m so f’ing sick of trying to screw around with network/routing problems with the new servers that I’m thinking about selling all my computers and going into construction.
Trying to fix arp routing issues is more than I ever wanted to know about networking… For example:
Jun 17 10:31:38 lb1 /kernel: arp: 192.168.1.20 is on em1 but got reply from 00:07:e9:xx:xx:xx on em0
Jun 17 10:32:13 lb1 last message repeated 63 times
Jun 17 10:34:13 lb1 last message repeated 157 times
Well that’s just super awesome… how about you just stop replying to the wrong network you little bitch of a server???!!?
The problem is that server A needs to talk to server B, but only THROUGH a local “gateway” (the gateway is a hardware load balancer). So fine… Server A goes through the gateway no problem. The gateway talks to server B no problem, but then server B tries to respond to server A directly (since it’s local) instead of going back through the gateway, and then server A doesn’t know where in the hell this incoming traffic is from because it never talked to server B (directly) to start with.
Okay… MySQL Cluster (the storage engine) kind of sucks IMO. It’s terribly annoying that you can’t alter the DB schema of anything running it (even more annoying is that you can’t alter the schema of a database that’s NOT using ndbcluster, but just exists in the same mysqld process). So I think I’m done with it (at least until they fix that and some other annoying thing).
So now I’m back to designing a MySQL Cluster using traditional storage engines (MyISAM and InnoDB). So let’s start with 4 DB servers and circular replication. (A -> B -> C -> D -> A). Okay… no problem there, especially now that MySQL has the following two variables (since 5.0.2) to prevent AUTO_INCREMENT collisions:
auto_increment_increment
auto_increment_offset
Okay, cool… just pipe MySQL client connections through the load balancers, and let it handle the failover/load balancing if needed.
But here’s the problem… if one of the servers fail, the replication chain is broken. For example if server B fails, C and D would never see anything that happened on server A. Not good.
So what about sending the replication network traffic through the load balancers as well? Then you could setup something like so: C replicates from B normally, but if B fails, then C replicates from A (automatically happening by routing replication traffic through load balancer).
Now I’m curious is if the load balancer network routing is fast enough to handle the interconnectivity of all the DB servers. I guess I’ll know soon enough (hopefully all the new equipment will be installed tomorrow or Friday).
I’ve had a few people email me asking for a picture of the new blade servers that are going to be taking over as web/database servers for digitalpoint.com soon…
So uhm… here is what they look like right now sitting on the floor in my spare bedroom.
From top to bottom, we have a 48 port gigabit switch (there is also a rack-mounted redundant power supply for the switch that I haven’t unpacked yet), 2 load balancers (one is a hot spare), then the good stuff… a blade chassis with 10 loaded blades. Total weight… more than a quarter ton. 🙂
I made all those stupid Ethernet cables by hand which was a pain! (okay, that’s a lie… I think Scott made one or two for me)
So what is in the blade chassis? 20 dual-core 2.8Ghz Xeon processors (112Ghz total), 120GB RAM, 20 x 146GB 15,000 rpm drives (2.9TB total). All 10 blades are running SuSE Linux Enterprise. This should be enough power to run my blog for awhile (hehe… kidding).
Okay, I think I’m relatively happy with how the first blade is configured for the new servers. So I split the RAID mirror today, and put one of the drives into the second blade and am letting them rebuild their RAID mirrors onto 2 new drives. So soon I’ll have 4 hard drives with the configuration/install, at which point I’ll have 8 blades build new mirrors. And just repeat that process until all 10 blade servers are up and running with the configuration (and then mirrored to each blade’s secondary drive for redundancy).
Either way, that means we are getting close to the blade servers being ready to go into the data center.
mpt-status is a command line utility to check the RAID status for LSI 1030 RAID controllers. Now can someone tell me why in the hell SuSE Linux Enterprise bothers to come with a version of mpt-status that doesn’t work with the Linux kernel that SuSE Linux uses???
It’s basically like bundling some application with Windows XP, but the application only works on Windows 98 or earlier.
Really annoying man…
After an hour of screwing around with it, I finally got it to work (I intentionally broke the RAID mirror to test the rebuild)…
Finally got the last (physical) piece for the blade servers (120GB RAM [60 x 2GB DIMMs]). I’m a swell counter because I counted them 5 or 6 times, and each time I counted them, I came up with 40, so I thought they shorted me 20 DIMMs for a 10 minutes or so. 🙂
So I was messing around with init.d, and wrote a script for it to automatically start the memcached daemon on boot. No biggie there, but this is a newer init.d than I had worked with in the past, and you can put comments in your script to easily enable/disable it for various run-levels. For example insserv -d memcached will configure init.d for the default run-levels defined within the script. Sweet, that’s pretty handy. I also got rsyncd (along with it’s init.d setup) up and running, so keeping the servers in sync should be cake.
Oh yeah… I had an interesting idea last night when doing all this stuff… why not configure all 10 blade servers identically (for example database servers have Apache and web content locally and web servers have database server processes installed). Then set an environment variable within /etc/profile.local along the lines of SYSTEM_TYPE = "database" (for database server). Then when the server boots, have it automatically configure itself as needed based on the SYSTEM_TYPE. That would make it super easy to change the job of a server on the fly. Just change the SYSTEM_TYPE variable and viola!, a database server could become a web server and added to the web cluster instantly. It would be even more interesting if the servers all monitored themselves, and if they were under heavy web load (but light on database), have one of the database servers automatically reset it’s SYSTEM_TYPE variable. Basically it would be automatic reallocation of servers/resources to whatever was needed at the time. Could be cool…
I spent most of the day getting crap installed on the first blade as well as learning about little quirks with SuSE Linux Enterprise 9.3.
MySQL 5.0.21 was an easy install (a nice little RPM for SuSE Linux comes from MySQL).
Memcached was a pretty easy compile/install… just needed to compile/install eventlib first.
The big bitch was getting PHP 5.1.4 compiled and working properly with all the options I wanted (had to install all sorts of secondary stuff that PHP had dependencies on [and then a lot of those things had their own dependencies that needed to be resolved]) and compiled a couple dynamic extensions for it (eAccelerator and Memcache). Most of the problems with the configure script not being able to find libraries it needed was solved with the –with-libdir=lib64 parameter.
I really hope that once the first blade is setup exactly how I want it, I can use the hardware RAID mirroring to just swap out one of the drives into another blade and rebuild the mirrors (and repeat for each blade)… then just set a unique IP address and hostname for each blade/server.
I still need to code some stuff to keep some of the files in sync properly (for example each web server should mirror content on each blade), but I’ll do that next week I guess.
Once the blades are all configured and ready to go, I can do some of the more fun stuff… like setting up the load balancers. I think I’m going to use the load balancers for both web and database connections for both load balancing and fault tolerance. So much good dorky fun!




 Did I tell you how much I hate the
Did I tell you how much I hate the 
 Anyone know of some super awesome secret way to make a 2Wire Internet gateway also act as a dynamic DNS client? Since it’s a
Anyone know of some super awesome secret way to make a 2Wire Internet gateway also act as a dynamic DNS client? Since it’s a  MySQL is working on version 5.0.25 already. 5.0.23 was never released, and 5.0.24 was released on July 27, 2006.
MySQL is working on version 5.0.25 already. 5.0.23 was never released, and 5.0.24 was released on July 27, 2006.


 So I was thinking about maybe doing MySQL fault tolerance and load balancing through hardware load balancers by setting up a virtual cluster for database reads and another for database writes. We could setup 2 master servers in a circular replication, making sure you only actually write to one at a time (define one as a hot spare in the load balancer’s “DB write cluster”, then the backup master takes over writes only if the primary master is down). That part is no problem… I don’ t have any questions there. 🙂
So I was thinking about maybe doing MySQL fault tolerance and load balancing through hardware load balancers by setting up a virtual cluster for database reads and another for database writes. We could setup 2 master servers in a circular replication, making sure you only actually write to one at a time (define one as a hot spare in the load balancer’s “DB write cluster”, then the backup master takes over writes only if the primary master is down). That part is no problem… I don’ t have any questions there. 🙂