For the last two months or so, I’ve been having a strange problem with my primary MySQL Server that required that the mysqld process (not the server itself) be restarted. The first image shows the CPU usage of the server, with the red arrows being the points I restarted the mysqld process (queries per second and types of queries do not change over time).

The server itself is a dual processor Xserve G5 with 5GB RAM, 1.2TB drive space, etc. so resources really are not an issue. Also, I should point out that no other services (like a web server) are running on the machine (it’s strictly MySQL only). Basically the longer the database server ran, the slower it would become (there are no “bad” queries anywhere either). After 24 hours it was slow enough that it needed to be restarted. I tried tweaking MySQL config options, throwing more memory at various aspects of MySQL.
While watching the processlist, I noticed something strange a few times. Something that should be blazingly fast (like an insert into a tiny HEAP table) was taking a VERY long time (sometimes 90 seconds), and not only that it was hanging all the query threads (even ones hitting unrelated databases). So then I had the idea to look at the query cache since that’s shared by all databases, and when you update a table, it needs to flush the queries from the cache for that table (which would explain why unrelated databases’ queries would hang while it was flushing the query cache for the HEAP table being updated). So to test this theory I rolled the query cache memory allocation from 256MB to 2MB. Low and behold… it worked! In my situation, the less memory you allocate to the query cache, the faster MySQL was. Then I remembered something that was added to Mac OS X 10.3 (I believe) and that’s the ulimit functionality. It’s actually a nice feature and can prevent a runaway process from taking down a machine. But in my case it was preventing MySQL (which really is the only process) from using very many resources. Still not sure why it would slowly get worse, but maybe it has to do with the more memory MySQL wanted to use over time, the more swap disk memory it was forced to use. Who knows… and to be honest, I don’t care, I’m just glad it works now.
Once I got that squared away, this is what my MySQL server CPU usage looks like:
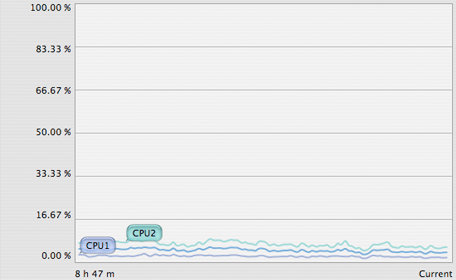
Now, hopefully someone out there will find themselves in the same problem and this will be your solution, rather than spend months screwing with it (this ulimit stuff would apply to other BSD variants like FreeBSD, not just Mac OS X).
Run this from the shell (as root):
sysctl -w kern.maxfiles=122880
sysctl -w kern.maxfilesperproc=102400
This allows a single process (mysqld in my case) to have up to 102,400 files open at once at the kernel level (more than enough).
Add this to your /etc/sysstl.conf file (or create it if needed):
kern.maxfiles=122880
kern.maxfilesperproc=102400
This makes the settings work when you reboot the machine.
Edit the /Library/StartupItems/MySQLCOM/MySQLCOM script that MySQL installs (it’s part of the automatic startup package), and somewhere near the beginning, add this:
ulimit -n 7000
ulimit -c unlimited
ulimit -d unlimited
ulimit -s 65536
You could put it somewhere else, but I chose this file since it doesn’t get overwritten when you upgrade MySQL. This lets the mysqld process use more than the default per user resources that Mac OS X Server allows.
You may want to adjust your settings as you see fit for your situation, but that’s what I used.
I’m just happy it’s no longer a problem for me!!!!! Yaaaayyy!!!!


 I’m looking at the possibility of moving some stuff I’m doing to blade servers. Anyone have any experience with blade servers in general? And if so, now is the time to gimme some input! 🙂
I’m looking at the possibility of moving some stuff I’m doing to blade servers. Anyone have any experience with blade servers in general? And if so, now is the time to gimme some input! 🙂