I had an issue where Googlebot was spidering parts of my site that were not allowed in the robots.txt file…
My old robots.txt file…
Disallow: /tools/suggestion/?
Disallow: /search.php
Disallow: /go.php
Disallow: /scripts/
Disallow: /ads/
User-agent: Googlebot
Disallow: /ebay_
Hmmmm… that’s weird… Googlebot is still spidering stuff it shouldn’t be…
www.digitalpoint.com 66.249.66.138 - - [14/Mar/2006:06:21:07 -0800] "GET /ads/ HTTP/1.1" 302 38 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +//www.google.com/bot.html)"
www.digitalpoint.com 66.249.66.138 - - [14/Mar/2006:10:26:18 -0800] "GET /ads/ HTTP/1.1" 302 38 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +//www.google.com/bot.html)"
www.digitalpoint.com 66.249.66.138 - - [14/Mar/2006:14:29:35 -0800] "GET /ads/ HTTP/1.1" 302 38 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +//www.google.com/bot.html)"
www.digitalpoint.com 66.249.66.138 - - [14/Mar/2006:17:47:21 -0800] "GET /ads/ HTTP/1.1" 302 38 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +//www.google.com/bot.html)"
So I made an inquiry to Google about this, and I actually heard back (nice!)…
we did examine your robots.txt file. Please be advised that it appears
your Googlebot entry in your robots.txt file is overriding your generic
User-Agent listing. We suggest you alter your robots.txt file by
duplicating the forbidden paths under your Googlebot entry:
User-agent: *
Disallow: /tools/suggestion/?
Disallow: /search.php
Disallow: /go.php
Disallow: /scripts/
Disallow: /ads/
User-agent: Googlebot
Disallow: /ebay_
Disallow: /tools/suggestion/?
Disallow: /search.php
Disallow: /go.php
Disallow: /scripts/
Disallow: /ads/
Once you’ve altered your robots.txt file, Google will find it
automatically after we next crawl your site.
Okay… I can live with that… easy fix. But check this out… Google’s own robots.txt testing tool within Google Sitemaps show the old robots.txt as being able to block Googlebot as expected.
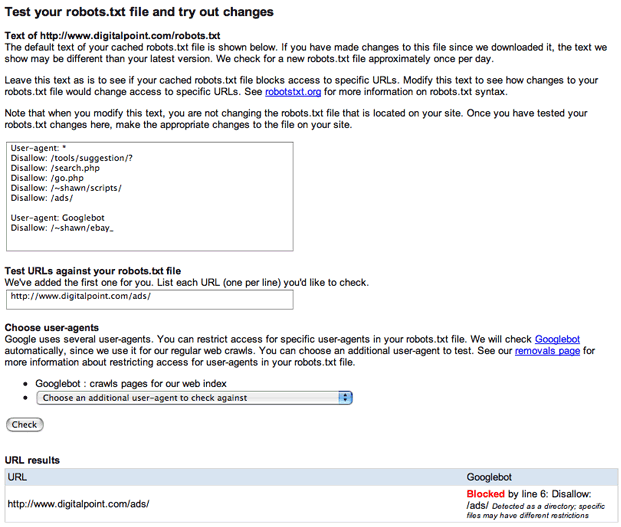
So how about some consistency here? And more importantly, if anyone at Google is reading this, how about someone tell me why my blog is banned in your index… 🙂
Looks like the Googlebot Spider algorithm is doing a match on the user-agent first, and if it passes that test, then don’t bother checking for “*” – tsk, tsk …
Looks like GoogleBot needs to pick it up and start recognizing * and not overwriting the new entries. That would be stupid if you needed to make separate entries just for Googlebot like that.
Actually, lastly too, you would hop on the lawsuit train with Kinderstart and all the companies and sue Google about deindexing you too 😛
>> how about someone tell me why my blog is banned in your index
Shoud’ve included that in the email, oh well
In general, I believe that if there is
– a generic User-Agent entry
– a more specific Googlebot entry
then we’ll go with the more specific entry for Googlebot. I’ll ask the Sitemaps team to check out the apparent difference between Sitemaps and Googlebot.
Matt
Could be that they’re using an older version of the file parser, and broke something in an update. Wouldn’t be the first time it’s happened to programmers ;P. Hmm, found your site by searching google too… Maybe was a temporary removal to immediatly flush the offending information, pending the next crawl?
/~Shawn is banned.
Why not move the folder?
Moving the folder doesn’t really solve the underlying problem of Google not liking something about my blog…
Huh?
Matt Cutts said: In general, I believe that if there is
– a generic User-Agent entry
– a more specific Googlebot entry
then we’ll go with the more specific entry for Googlebot. I’ll ask the Sitemaps team to check out the apparent difference between Sitemaps and Googlebot.
Actually, the correct way to do this is to check BOTH of them. I.e. if you are disallowed in either the generic OR specific case, then the spider should not poke around … which is another way of echo’ing my first comment.
You might be interested in this thread: http://groups.google.com/group/google-sitemaps/browse_thread/thread/19d8841e9575c37e.